

前回のブログの投稿が2016-11-15。
四半期近くブログをサボっていたことになります。
やっぱり一週間に1回更新するのって無理があると思います。
頑張りましょう。統計を学べば色々書けるはず。
何かネタは無いかと考えた結果
「そういえば主成分分析って書いたこと無いよね」
と思い当たりました。
0.主成分分析とは
(Python・Rを使えば)計算が簡単で、それっぽい結果が出る頼もしい統計方法です。
多変量データを統合して、新たな指標を算出できます。
詳しく解説するとボロが出そうなので今回は触り程度に。少し脚色しています。
例えばこんなデータ
・とあるレストランのアンケート結果
| 味 | 接客 | 値段 | メニュー | |
| 顧客A | 5 | 2 | 3 | 2 |
| 顧客B | 4 | 1 | 2 | 1 |
| 顧客C | 3 | 3 | 3 | 5 |
| 顧客D | 2 | 2 | 3 | 4 |
| 顧客E | 5 | 2 | 5 | 1 |
| 顧客F | 4 | 3 | 2 | 3 |
何となく
顧客Aと顧客Bは同じ価値観?
顧客Cと顧客Dは同じ価値観?
一人だけ値段を「5」にしている顧客Eは特殊?
といった印象を持つのですがいまいち説得力が出ません。
かといって変数が4つもあるので図にするのも難しいです。
そこで次元を縮小して作図できるような値に直します。
| 第一軸 | 第二軸 | |
| 顧客A | -1.2 | 0.0 |
| 顧客B | -1.5 | -1.6 |
| 顧客C | 2.5 | 0.7 |
| 顧客D | 2.0 | 00 |
| 顧客E | -2.4 | 1.6 |
| 顧客F | 0.6 | -0.6 |
これなら散布図が作れます。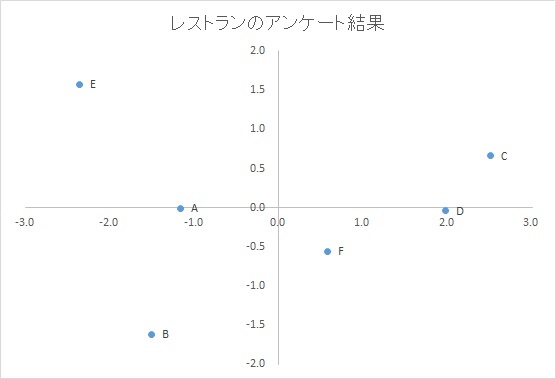
あとは
縦軸・横軸が何を示しているのか
どのようなグループがあるのか
といったことを分析していきます。
今回だと(データが少ないので言い切れない部分もありますが)
・横軸
全体的な満足度。右に行くほど満足している顧客。
・縦軸
値段の満足度?
ということが分かりますね。
「顧客Cと顧客Dは価値観が似ているので、このグループ向けのイベントをしてみよう」といった計画も立てられるわけです。
もうここまで書いたらコーヒーの分析って不要な気がしてきました。
1.使用するデータ
個人的にお世話になっている
world beans shop
のコーヒー豆の味のパラメータを使用します。
このお店では四つの成分
甘味・酸味・苦味・コク
で表現されています。それぞれ0~5の数値です。
この4つの変数の値と豆の種類のデータを使わせてもらいました。
2.解析
取得したデータがコチラ。
スタンダートコーヒーのデータです。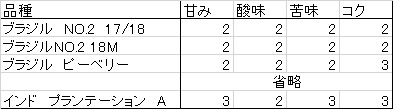
これをsklearnのPCAに放り込めば2次元に縮小されたデータが取り出せます。
散布図にすると以下のようになりました。
四つの成分の数値が同じ商品が何個かあり、そこは重なっています。
想像以上にバラバラに配置されましたね。
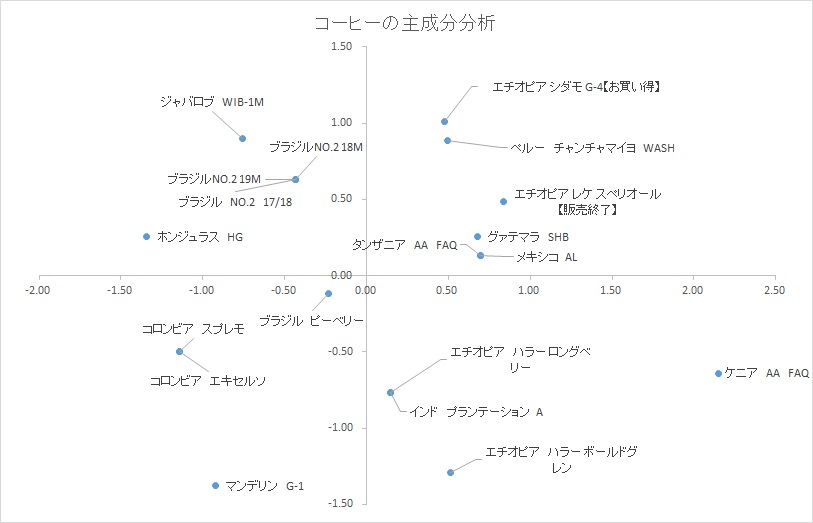
・横軸
成分の全体量ですね。
左はあまり主張しないコーヒー、右に行くと個性的な(成分の値が高い)コーヒーと思われます。
品種的にも左はブラジル・コロンビア産、右にはエチオピア産(モカ)・ケニア産(キリマンジャロ)なので納得できる感じです。
・縦軸
何でしょうコレ?
「コク」っぽい感じはするんですけど・・・上はあっさり系で、下は濃い感じでしょうか。
四つの成分の割合の寄り具合にも関係してそうです。
全ての品種の味が分からないので特定は難しいですね。
3.まとめ
主成分分析で、複数の成分を持つデータから解釈しやすいデータへの変換ができました。
散布図が何を示しているかは、もっと踏み込んだ解析が必要ですね。無視してる係数もありますし・・・。
何にせよ散布図に直すと気持ちが良いですね。
「グァテマラが美味しかったから、傾向が似ているタンザニアAAを注文しよう。」
「逆に真逆の位置にあるコロンビアを注文するか・・・」
と色々考えることが出来ます。