

年末に選挙・・・ですが、
自分の住んでいる地域は
自販機にカブトムシが集まり
季節の変わり目に堆肥の匂いが漂い
小学校の授業でメダカの代わりに蚕を育てる
横浜の中では僻地に入るので、特に五月蝿くはなりません。
TwitterAPIを学び始めたので、大量のツイート文が入手できるようになりました。
前々から興味のあったネガポジ判定を含めて、簡単な解析をしていきたいと思います。
政党へのツイート文を解析していますが、
どこの政党を貶めてやろう
どこの政党を褒め称えよう
といった趣旨は一斉含んでおりません。
・比較ができる
・整った文章が多い
・ツイートの更新が早い
といった条件で、政党へのツイートは解析に適しています。
1.ネガポジ判定とは
ネガティブ・ポジティブな言葉を文章中から読み取り分析することです。
「今日は最悪な日。雨も降っていたし、でも弁当は美味しかった。」
という文では
ポジティブワードは『美味しかった』、
ネガティブワードは『今日・最悪・日・雨・降る・弁当』になります。
また単語毎に点数があり、それで優劣や比較ができるようになっている場合もあります。
喜ぶ:よろこぶ:動詞:0.999979
幸運:こううん:名詞:0.995019
腹痛:ふくつう:名詞:-0.4475
苦しい:くるしい:形容詞:-0.999788
といったふうに良い言葉であれば1に近く、悪い言葉であれば-1に近くなっています。
今回は、こちらの単語感情極性対応表を使わせて頂きました。
2.下準備
Pythonを用いたTwitterAPI1.1にて、各政党に対するツイート文を取得していきます。
自民党(to:jimin_koho) 100件
民主党(to:dpjnews) 100件
公明党(to:komei_koho) 100件
維新の党(to:ishinnotoh) 50件
次世代の党(to:j_pfg) 100件
日本共産党(to:jcp_cc) 57件
広報のアカウントしかない党もありました。
党のアカウント・広報のアカウント両方ある場合は、広報のアカウントで選出します。
自分の知識不足か、TwitterAPIの不具合か・・・取得できたツイート文に偏りがあります。
維新の党、日本共産党は100件以下のツイート文になります。
3.解析方法
単語感情極性対応表に基づきネガポジ判定を行います。
①ツイート文を分かち書きをして、終止形に直します。
②単語が対応表にあればその点数を当てはめます。
③数値の合計を単語数で割り平均を出します。
例えば
「今日は最悪な日。雨も降っていたし、でも弁当は美味しかった。」
というツイート文なら
①今日 は 最悪 だ 日 雨 も 降る て いる た し でも 弁当 は 美味しい た
②今日(0.17) 最悪(-0.99) 日(-0.95) 雨(-0.95) 降る(-0.99) 弁当(-0.46) 美味しい(0.99)
③(0.17-0.99-0.95-0.95-0.99-0.46+0.99)/7=-0.45
となります。
ツイート文の単語が対応表にないと数値が0になってしまうのが欠点ですが…。
とりあえずこれで解析を行います。
4.結果
ヒストグラムでどのように分布しているかをグラフ化しました。
衆議院の議席配分順に並べると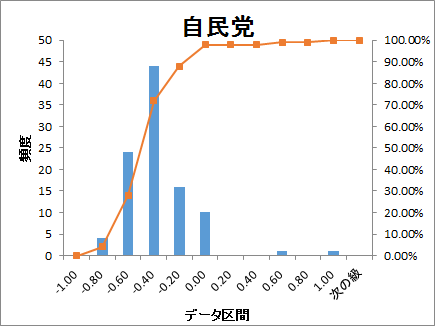
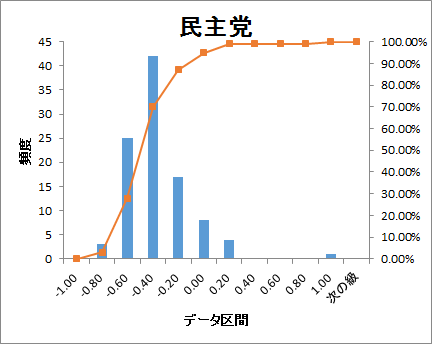
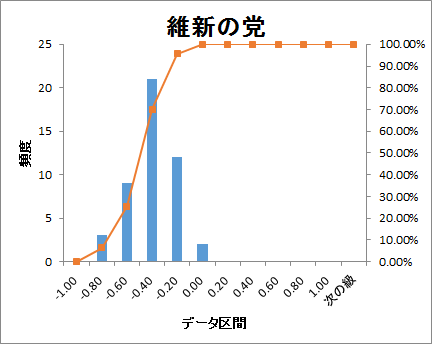
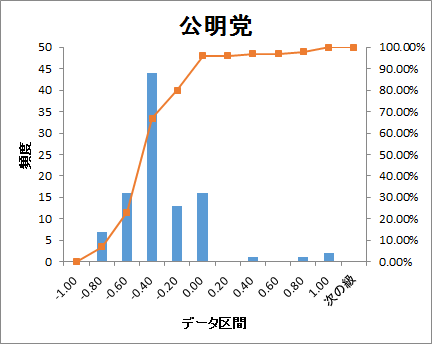
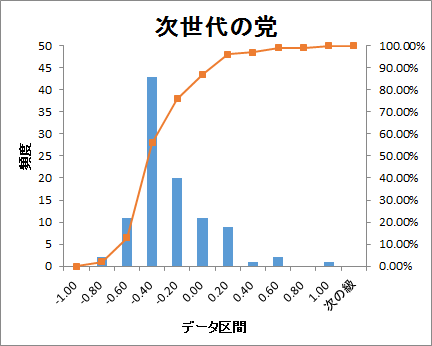
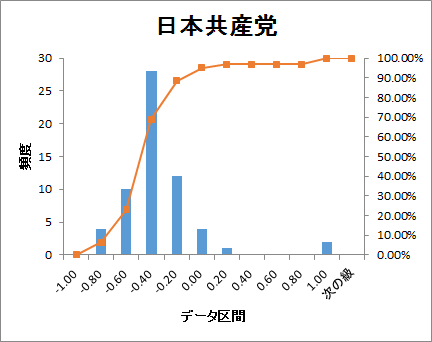
どの政党も-0.60~-0.40の範囲が最も頻度が高くなっています。
参考にした単語感情極性対応表がネガティブワードの登録が多いので、
これは正常な結果とも考えられます。
議席の多い自民・民主党へのツイート文は、ややネガティブ色が強いようにも見えます。
最頻度の-0.60~-0.40を基準にして、
それより下(-1.00~-0.60)の数値をネガティブな発言、
それより上(-0.40~1.00)の数値をポジティブな発言と仮定をしてグラフを作成します。
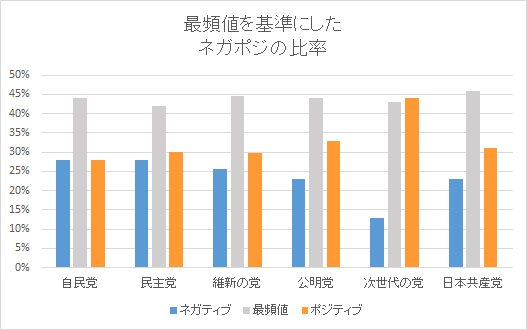
こうしてみると
議席が多い党はネガティブ≒ポジティブになり、
野党・新党はネガティブ<ポジティブになる傾向があるようです。
次世代の党には期待が寄せられているのでしょうか…
ポジティブな政策についての発言が多いということも考えられます。
ヒストグラムが同じようなグラフになった時は、ガッカリしましたが
それっぽい結果を出すことが出来ました。
5.課題
参考にした単語感情極性対応表では、
ネガティブの単語が多く、ポジティブの10倍ほど登録されているので
どうしてもネガティブよりの数値になってしまいます。
また打ち消しを無視しているので
「心配しないで」と「心配だ」は、同じ数値になってしまいます。
ツイート文の解析に関して
今回は、誰が発言したかは区別を行っていません。
よって同じ人物が同じような内容の発言を繰り返した場合、
結果に偏りが出てくる可能性が考えられます。
しかし炎上もTwitterの特色ですから・・・どう処理すればいいのか悩みます。